In SPSS, rank transforms and percentile groupings can be computed using the Rank Cases procedure. To open Rank Cases, click Transform > Rank Cases.
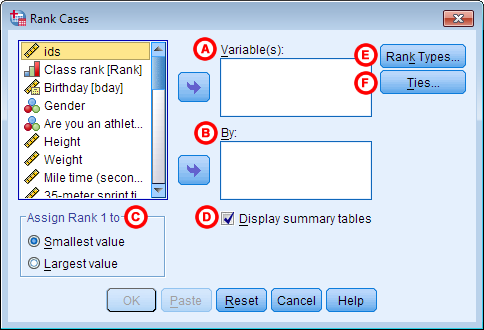
A Variables: The variables to compute rank transforms on. The new ranks will be saved to new variables (whose names will be automatically generated).
B By: (Optional) Assign ranks within groups. By variables should be nominal or ordinal, and have a small number of categories.
C Assign Rank 1 to: Should ranks be assigned in increasing or decreasing order? By default, ranks are assigned by ordering the data values in ascending order (smallest to largest), then labeling the smallest value as rank 1. Alternatively, Largest value orders the data in descending order (largest to smallest), and assigns the largest value the rank of 1.
D Display summary tables: When checked, a summary of the new rank variables is printed to the Output window. The summary includes the original variables, the name of the new variables, the rank order, the ranking method, and the method used for ties. This option is on by default.
E Rank types: (Optional) Choose one or more formulas to compute the ranks. Each box you check on this screen will add another rank variable to your dataset.

By default, only the "Rank" option is selected; this computes simple ranks. The "Ntiles" option will produce percentile-based groupings: for example, Ntiles=2 will perform a median split; Ntiles=4 will produce quartiles; Ntiles=10 will produce decile groups.
For details about the other rank types and the proportion estimation formulas, please see the official SPSS documentation for Rank Cases. Note that the Proportion Estimation Formula options are inactive unless Proportion estimates and/or Normal scores are selected.
F Ties: How should ranks be assigned in the case of ties? (A tie occurs when two or more observations share the exact same value.) There are four options for how to resolve ties: Mean, Low, High, and Sequential ranks to unique values. By default, mean ranks are assigned to ties.

- Mean - First, the observations are ordered and given unique, sequential ranks. Then, tied observations have their assigned ranks averaged together.
- Low - First, the observations are ordered and given unique, sequential ranks. Then, the ranks of any ties are re-assigned to the value of the smallest rank.
- High - First, the observations are ordered and given unique, sequential ranks. Then, the ranks of any ties are re-assigned to the value of the largest rank.
- Sequential ranks to unique values - First, the observations are ordered. Unique ranks are assigned in order until a tie is encountered. Ties receive the same rank until the next unique value appears. (The actual number of unique ranks assigned is therefore equal to the number of unique values.)
