Problem Statement
In general, human heights tend to be normally distributed, but human weights tend to be right-skewed. How can we check if our sample data follow these patterns?
Let's use the Explore procedure to look at a normally distributed variable and a non-normally distributed variable.
Running the Procedure
Using the Explore Dialog Window
- Click Analyze > Descriptive Statistics > Explore.
- Add variables Height and Weight to the Dependent List box.
- Click Plots. Check the box next to Normality plots with tests. Click Continue.
- Click Options. Change the missing value handling to Exclude cases pairwise. Click Continue.
- When finished, click OK.
Using Syntax
EXAMINE VARIABLES=Height Weight
/PLOT BOXPLOT HISTOGRAM NPPLOT
/COMPARE GROUPS
/STATISTICS DESCRIPTIVES
/CINTERVAL 95
/MISSING PAIRWISE
/NOTOTAL.
Output
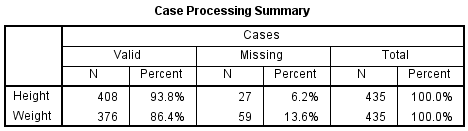
The first table, the Case Processing Summary, shows how many valid values there were. Since we selected pairwise missing data handling, the analysis is using all complete information for each variable. We can see that there are more missing values for variable Weight (59) than there are for variable Height (27).
The Descriptives box appears next. It has detailed univariate descriptive statistics for each of the continuous variables, including skewness and kurtosis.
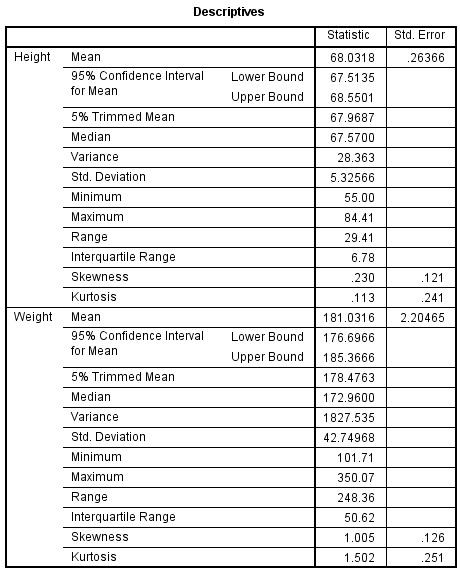
The standard normal distribution has skewness = 0 and kurtosis = 0, so we can interpret the sample skewness and kurtosis of our variables in relation to that. For height, the skewness is .23 (slightly right skewed) and the kurtosis is .113 (slightly heavier tails than a normal distribution, but not by much). For weight, the skewness is about 1 (right skewed) and the kurtosis is 1.5 (heavier tails than a normal distribution). These numbers alone aren't very good indicators of departures from normality, but they can supplement the graphs and the normality tests.
The Tests of Normality table contains the Kolmogorov-Smirnov and Shapiro-Wilk tests for both of our variables.
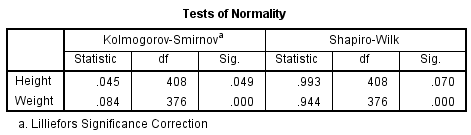
For weight, the K-S and Shapiro-Wilk test p-values are both very small (p < 0.001), so the decision to reject is very clear. However, for height, the results are not as clear-cut: the K-S p-value is p = 0.049 (which is just barely below the significance level 0.05), and the Shapiro-Wilk p-value is p = 0.070. These tests are suggesting contradictory conclusions: The K-S tests suggests non-normality, but the Shapiro-Wilk test suggests normality. How do we resolve this discrepancy? Let's look at the graph output.
The plots for variable weight make it very clear why the normality tests came back significant:
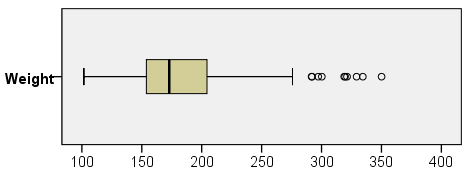
The boxplot of weight shows that the distribution is skewed right. Signals of this include:
- Shorter left tail, longer right tail
- Median (the center line in the box) is left of center
- Outliers on the high end of the distribution
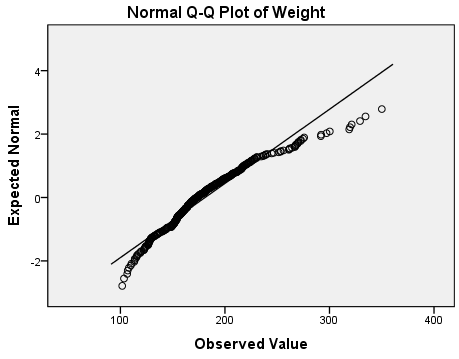
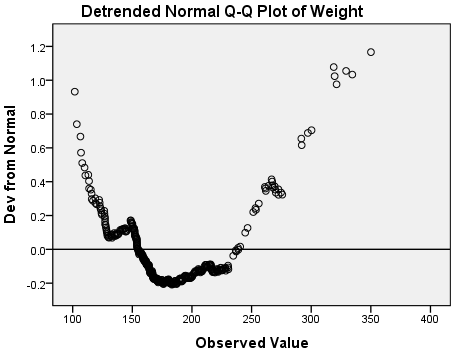
The Q-Q and detrended Q-Q plots show systematic deviations from normality: notice that the overall shape of the detrended plot is parabolic (U-shaped). Also notice that the deviations from normality are relatively large: the y-axis of the detrended normal q-qplot indicates that the deviations range in magnitude from -0.2 to 1.2.
With that in mind, let's evaluate the graphs for variable height:
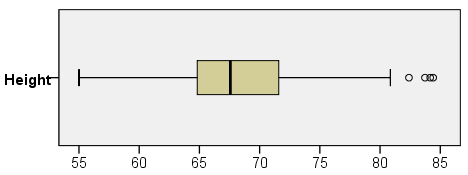
The right and left tails appear to be about the same length. There are some outliers on the high end, and the median is slightly left of center; however, it's not nearly as severe as it was for the weights. In general, the heights appear to be symmetrically distributed about the center of the distribution.
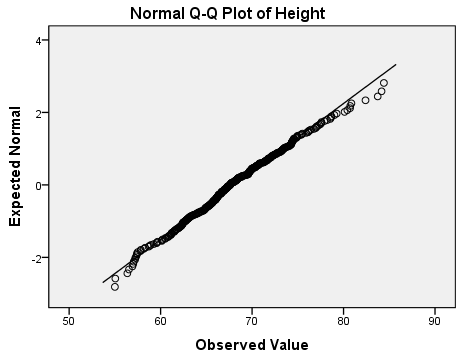
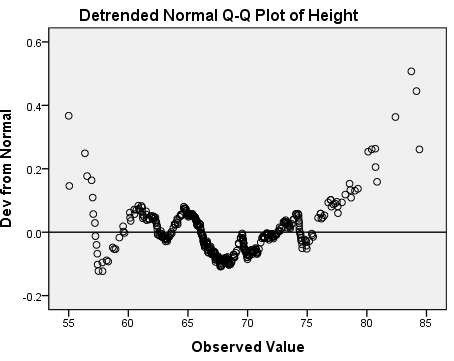
The normal Q-Q plot shows that almost all of the observed height values are the same as what we would expect if this data were normally distributed. The deviations appear to mostly occur in the tails. The detrended normal Q-Q plot acts as a magnifying glass for this, allowing us to see just how strong the existing deviations are: the y-axis of this plot shows that the deviations from normality range from -0.2 to 0.6. There's no obvious trend to the deviations like we saw for the weights.
Discussion and Conclusion
Between the skewness in the boxplot, the strong and systematic deviations in the Q-Q plots, and the two significant normality tests (p < 0.001), we have overwhelming evidence suggesting that variable Weight is not normally distributed.
For variable height, the evidence is much weaker. One test is significant (K-S test p = 0.049); the other is not (Shapiro-Wilk p = 0.070). After looking at the graphs, we see that there are some deviations from normality, but they do not appear to be very large. For practical purposes, then, it is not unreasonable to assume that variable height is normally distributed.
There are several hypothesis tests that can be used to test for normality. However, it is important to not rely on these tests alone: you should always use graphical measures like boxplots, histograms, and P-P plots to corroborate them.






















