Problem Statement
According to the CDC, the mean height of U.S. adults ages 20 and older is about 66.5 inches (69.3 inches for males, 63.8 inches for females).
In our sample data, we have a sample of 435 college students from a single college. Let's test if the mean height of students at this college is significantly different than 66.5 inches using a one-sample t test. The null and alternative hypotheses of this test will be:
H0: µHeight = 66.5 ("the mean height is equal to 66.5")
H1: µHeight ≠ 66.5 ("the mean height is not equal to 66.5")
Before the Test
In the sample data, we will use the variable Height, which a continuous variable representing each respondent’s height in inches. The heights exhibit a range of values from 55.00 to 88.41 (Analyze > Descriptive Statistics > Descriptives).
Let's create a histogram of the data to get an idea of the distribution, and to see if our hypothesized mean is near our sample mean. Click Graphs > Legacy Dialogs > Histogram. Move variable Height to the Variable box, then click OK.
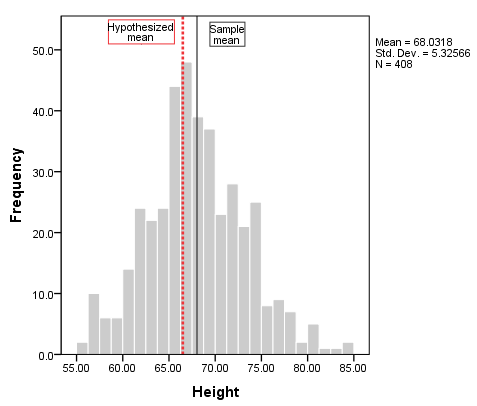
To add vertical reference lines at the mean (or another location), double-click on the plot to open the Chart Editor, then click Options > X Axis Reference Line. In the Properties window, you can enter a specific location on the x-axis for the vertical line, or you can choose to have the reference line at the mean or median of the sample data (using the sample data). Click Apply to make sure your new line is added to the chart. Here, we have added two reference lines: one at the sample mean (the solid black line), and the other at 66.5 (the dashed red line).
From the histogram, we can see that height is relatively symmetrically distributed about the mean, though there is a slightly longer right tail. The reference lines indicate that sample mean is slightly greater than the hypothesized mean, but not by a huge amount. It's possible that our test result could come back significant.
Running the Test
To run the One Sample t Test, click Analyze > Compare Means > One-Sample T Test. Move the variable Height to the Test Variable(s) area. In the Test Value field, enter 66.5.

Click OK to run the One Sample t Test.
Syntax
If you are using SPSS Statistics 27 or later:
T-TEST
/TESTVAL=66.5
/MISSING=ANALYSIS
/VARIABLES=Height
/ES DISPLAY(TRUE)
/CRITERIA=CI(.95).
If you are using SPSS Statistics 26 or earlier:
T-TEST
/TESTVAL=66.5
/MISSING=ANALYSIS
/VARIABLES=Height
/CRITERIA=CI(.95).
Output
Tables
Two sections (boxes) appear in the output: One-Sample Statistics and One-Sample Test. The first section, One-Sample Statistics, provides basic information about the selected variable, Height, including the valid (nonmissing) sample size (n), mean, standard deviation, and standard error. In this example, the mean height of the sample is 68.03 inches, which is based on 408 nonmissing observations.

The second section, One-Sample Test, displays the results most relevant to the One Sample t Test.

A Test Value: The number we entered as the test value in the One-Sample T Test window.
B t Statistic: The test statistic of the one-sample t test, denoted t. In this example, t = 5.810. Note that t is calculated by dividing the mean difference (E) by the standard error mean (from the One-Sample Statistics box).
C df: The degrees of freedom for the test. For a one-sample t test, df = n - 1; so here, df = 408 - 1 = 407.
D Significance (One-Sided p and Two-Sided p): The p-values corresponding to one of the possible one-sided alternative hypotheses (in this case, µHeight > 66.5) and two-sided alternative hypothesis (µHeight ≠ 66.5), respectively. In our problem statement above, we were only interested in the two-sided alternative hypothesis.
E Mean Difference: The difference between the "observed" sample mean (from the One Sample Statistics box) and the "expected" mean (the specified test value (A)). The sign of the mean difference corresponds to the sign of the t value (B). The positive t value in this example indicates that the mean height of the sample is greater than the hypothesized value (66.5).
F Confidence Interval for the Difference: The confidence interval for the difference between the specified test value and the sample mean.
Decision and Conclusions
Recall that our hypothesized population value was 66.5 inches, the [approximate] average height of the overall adult population in the U.S. Since p < 0.001, we reject the null hypothesis that the mean height of students at this college is equal to the hypothesized population mean of 66.5 inches and conclude that the mean height is significantly different than 66.5 inches.
Based on the results, we can state the following:
- There is a significant difference in the mean height of the students at this college and the overall adult population in the U.S. (p < .001).
- The average height of students at this college is about 1.5 inches taller than the U.S. adult population average (95% CI [1.013, 2.050]).



