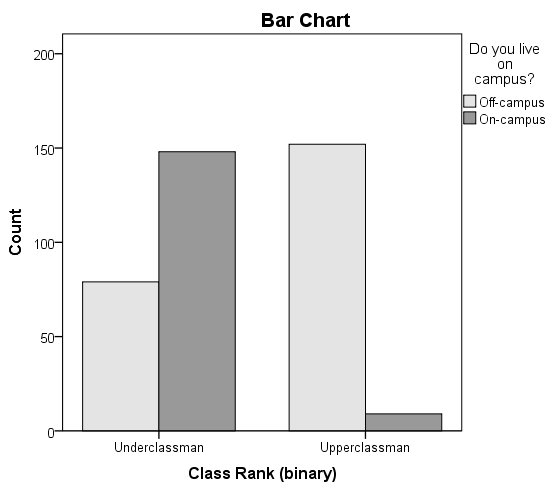
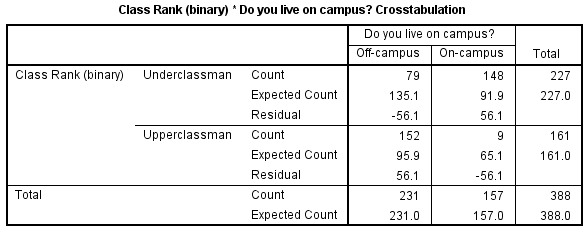
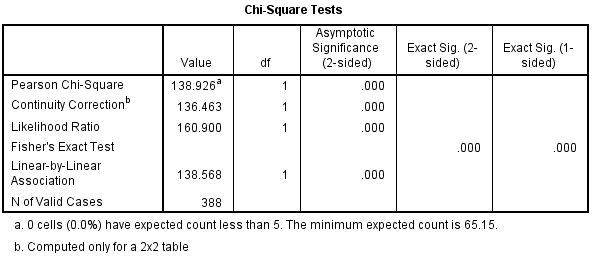
In SPSS, the Chi-Square Test of Independence is an option within the Crosstabs procedure. Recall that the Crosstabs procedure creates a contingency table or two-way table, which summarizes the distribution of two categorical variables.
To create a crosstab and perform a chi-square test of independence, click Analyze > Descriptive Statistics > Crosstabs.

A Row(s): One or more variables to use in the rows of the crosstab(s). You must enter at least one Row variable.
B Column(s): One or more variables to use in the columns of the crosstab(s). You must enter at least one Column variable.
Also note that if you specify one row variable and two or more column variables, SPSS will print crosstabs for each pairing of the row variable with the column variables. The same is true if you have one column variable and two or more row variables, or if you have multiple row and column variables. A chi-square test will be produced for each table. Additionally, if you include a layer variable, chi-square tests will be run for each pair of row and column variables within each level of the layer variable.
C Layer: An optional "stratification" variable. If you have turned on the chi-square test results and have specified a layer variable, SPSS will subset the data with respect to the categories of the layer variable, then run chi-square tests between the row and column variables. (This is not equivalent to testing for a three-way association, or testing for an association between the row and column variable after controlling for the layer variable.)
D Statistics: Opens the Crosstabs: Statistics window, which contains fifteen different inferential statistics for comparing categorical variables.

To run the Chi-Square Test of Independence, make sure that the Chi-square box is checked.
E Cells: Opens the Crosstabs: Cell Display window, which controls which output is displayed in each cell of the crosstab. (Note: in a crosstab, the cells are the inner sections of the table. They show the number of observations for a given combination of the row and column categories.) There are three options in this window that are useful (but optional) when performing a Chi-Square Test of Independence:

1Observed: The actual number of observations for a given cell. This option is enabled by default.
2Expected: The expected number of observations for that cell (see the test statistic formula).
3Unstandardized Residuals: The "residual" value, computed as observed minus expected.
F Format: Opens the Crosstabs: Table Format window, which specifies how the rows of the table are sorted.