Subsets can be created using either inclusion or exclusion criteria. Inclusion and exclusion criteria are both statements of conditional logic that are based on one or more variables, and one or more values of those variables.
Creating a subset that contains only records with a certain value: In this case, your subset will keep the records that meet the criteria you specify. The criteria for keeping an observation is called the inclusion criteria.
DATA New-Dataset-Name (OPTIONS);
SET Old-Dataset-Name (OPTIONS);
IF (insert conditions) THEN OUTPUT;
RUN;
Creating a subset that contains only records without a certain value: In this case, your subset will be all of the cases that remain after dropping observations with "disqualifying" values. The "disqualifying" values you specify are called the exclusion criteria.
DATA New-Dataset-Name (OPTIONS);
SET Old-Dataset-Name (OPTIONS);
IF (insert conditions) THEN DELETE;
RUN;
The inclusion or exclusion criteria appear after the IF statement.
Example - Delete cases with a specific value
Let's create a subset of the sample data that doesn't contain any freshmen students. To do this, we can use the DELETE keyword to remove observations where Rank = 1, which is the indicator value for freshman.
DATA sample_small;
SET sample;
IF (Rank = 1) THEN DELETE;
RUN;
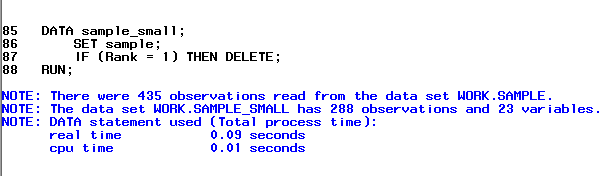
The resulting subset has 288 observations. (Can you name what groups of students are included in this subset? Hint: there are four different groups.)
Example - Extract cases matching a logical condition
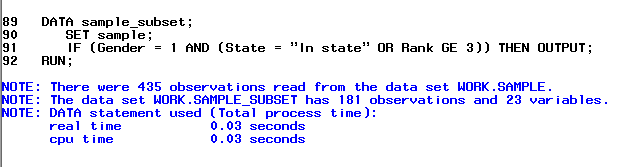
Conditional logic can get very complex, particularly when the criteria are based on multiple variables and/or multiple values. For example, how would we write the conditional logic for a subset containing only male students, and that live in-state or are at least juniors? In this case, there are three criteria variables: gender, state residency, and class rank. Every subject included in the subset must be male, and in addition to being male, the subject must either a) be an in-state student, or b) be "at least a junior" -- i.e., a junior or a senior.
The code required to make this subset is given below. Notice that you can use multiple sets of parentheses to group conditional statements. The parentheses identify the "order of operations" in terms of how the conditional logic statement is read. In this case, it's mandatory that everyone in the subset be male; after that, they can either be in-state students or at least juniors.
DATA sample_subset;
SET sample;
IF (Gender = 1 AND (State = "In state" OR Rank GE 3)) THEN OUTPUT;
RUN;
Notice how state residency and class rank are placed in their own set of parentheses.
After running the block of code, you should see that the new subset has “sample_subset” has 181 observations, corresponding to the number of students that met the inclusion criteria.
Example - Delete cases with specific conditions (numeric and character variables)
Now let’s say we want to exclude freshmen students that are also in-state students. (That means that our subset will contain all sophomores, all juniors, all seniors, all students with missing class rank values, and out-of-state freshmen.)
DATA sample_small;
SET sample;
IF (Rank = 1 AND State = "In state") THEN DELETE;
RUN;

Example - Keep cases having values within a specific range
Now let's say we want to include only the observations whose Math scores fall between 55 and 75. On paper, we can write this condition using the notation $$55 \leq x \leq 75.$$ However, SAS does not recognize this notation. Instead, we must rewrite this as two conditions $$ x \geq 55$$ and $$x \leq 75$$ joined with an AND statement.
DATA sample_math;
SET sample;
IF (Math GE 55 AND Math LE 75) THEN OUTPUT;
RUN;
After running the block of code, you should see that the new subset "sample_math" has 330 observations, corresponding to the number of students who met the inclusion criteria.

If you want to make sure that the procedure works, you can compute the mean of the variable from the new dataset and see if the data falls between the specified range.
PROC MEANS data=sample_math;
VAR Math;
RUN;

As you can see, the observations for the Math variable are within the 55 to 75 range that we specified.














