Recall that in our sample dataset, the variable State is a nominal categorical variable (representing whether the student is an in-state or out-of-state student), while variable Rank is an ordinal categorical variable (representing the student's class rank).
- A nominal categorical variable's categories do not have any intrinsic order.
- An ordinal categorical variable's categories can be ordered in a meaningful way.
Recall also that State is a string variable, and Rank is a numeric variable. This simply means that the observations for Rank were recorded as numbers (with value labels applied later), while the observations for State were recorded as characters (strings). This example will show that PROC FREQ works for both types of variables.
Problem Statement
Create frequency tables for the variables State and Rank.
Syntax
PROC FREQ DATA=sample;
TABLE State Rank;
RUN;
Output
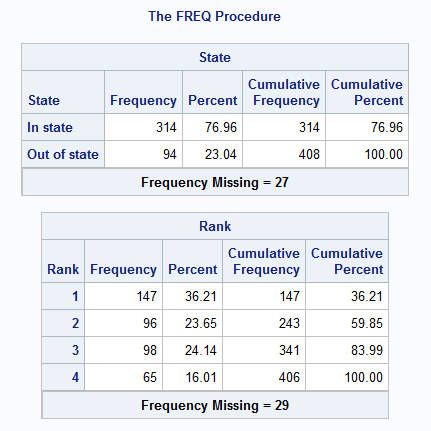
PROC FREQ creates one frequency table per variable. Each frequency table contains four columns of summary measures:
- The Frequency column indicates how many observations fell into the given category.
- The Percent column indicates the percentage of observations in that category out of all nonmissing observations.
- The Cumulative Frequency column is the number of observations in the sample that have been accounted for up to and including the current row. It can be computed by adding all of the numbers in the Frequency column above and including the current row.
- The Cumulative Percent column is the proportion of the sample that has been accounted for up to and including that row. It can be computed by adding all of the numbers in the Percent column up to the current row.
If there are cases with missing values for the variable, the number of missing values are given below the table.
If you do not specify an ORDER option in the PROC FREQ statement, the frequency table will be sorted by the values of the categories. This means that, for string variables, the categories will be ordered alphabetically, while numeric variables, the categories will be ordered from smallest to largest number code.
Problem Statement
Suppose we want to create frequency tables, but we'd also like to know the number of distinct categories for each variable. (This can be useful if you have a variable with many categories, where the number of rows in the frequency table can't easily be determined by a quick scan.)
To do this, we add the NLEVELS option to the PROC FREQ statement.
Syntax
PROC FREQ DATA=sample NLEVELS;
TABLE State Rank;
RUN;
Output
Adding the NLEVELS option to our syntax will add one new table to the output, right at the beginning:

The new table shows how many "nonmissing levels" (i.e., observed categories) and how many "missing levels" (i.e., how many special missing value codes were present in the data). For variable State, there are two nonmissing levels; for variable Rank, there are four nonmissing levels. These are easily confirmed by scanning the rows of the corresponding frequency tables.




