Problem Statement
Perhaps you would like to test whether there is a statistically significant linear relationship between two continuous variables, weight and height (and by extension, infer whether the association is significant in the population). You can use a bivariate Pearson Correlation to test whether there is a statistically significant linear relationship between height and weight, and to determine the strength and direction of the association.
Before the Test
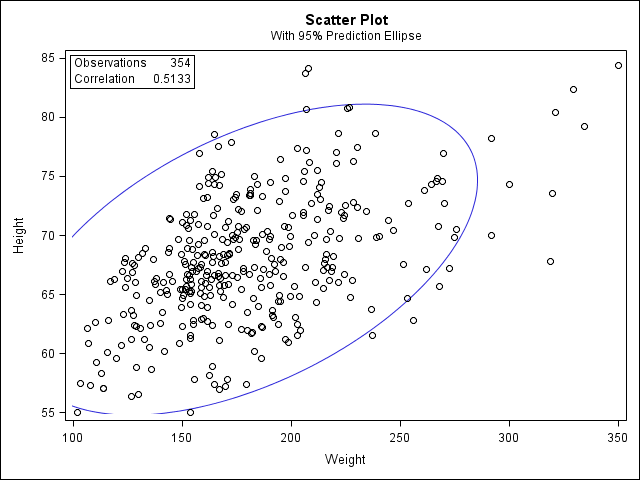
Before we look at the Pearson correlations, we should look at the scatterplots of our variables to get an idea of what to expect. In particular, we need to determine if it's reasonable to assume that our variables have linear relationships. PROC CORR automatically includes descriptive statistics (including mean, standard deviation, minimum, and maximum) for the input variables, and can optionally create scatterplots and/or scatterplot matrices. (Note that the plots require the ODS graphics system. If you are using SAS 9.3 or later, ODS is turned on by default.)
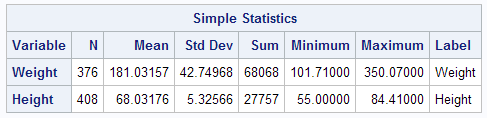
In the sample data, we will use two variables: “Height” and “Weight.” The variable “Height” is a continuous measure of height in inches and exhibits a range of values from 55.00 to 84.41. The variable “Weight” is a continuous measure of weight in pounds and exhibits a range of values from 101.71 to 350.07.
Running the Test
SAS Program
PROC CORR DATA=sample PLOTS=SCATTER(NVAR=all);
VAR weight height;
RUN;
Output
Tables
The first two tables tell us what variables were analyzed, and their descriptive statistics.

The third table contains the Pearson correlation coefficients and test results.
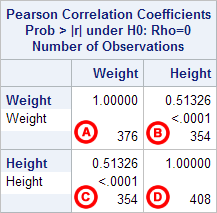
Notice that the correlations in the main diagonal (cells A and D) are all equal to 1. This is because a variable is always perfectly correlated with itself. Notice, however, that the sample sizes are different in cell A (n=376) versus cell D (n=408). This is because of missing data -- there are more missing observations for variable Weight than there are for variable Height, respectively.
The important cells we want to look at are either B or C. (Cells B and C are identical, because they include information about the same pair of variables.) Cells B and D contain the correlation coefficient itself, its p-value, and the number of complete pairwise observations that the calculation was based on.
In cell B (repeated in cell C), we can see that the Pearson correlation coefficient for height and weight is .513, which is significant (p < .001 for a two-tailed test), based on 354 complete observations (i.e., cases with nonmissing values for both height and weight).
Graphs
If you used the PLOTS=SCATTER option in the PROC CORR statement, you will see a scatter plot:
Decision and Conclusions
Based on the results, we can state the following:
- Weight and height have a statistically significant linear relationship (r = 0.51, p < .001).
- The direction of the relationship is positive (i.e., height and weight are positively correlated), meaning that these variables tend to increase together (i.e., greater height is associated with greater weight).
- The magnitude, or strength, of the association is moderate (.3 < | r | < .5).







